반응형
파이썬(v3.9)으로 크롤링하는 예제를 간단히 남겨본다. 개발 환경은 아래와 같다
크롤링에 필요한 패키지 설치를 위해 requirements.txt 파일을 작성한다. python에서 클로링을 위해서 beautifulsoup을 많이 활용한다.
beautifulsoup4==4.12.2
requests==2.31.0그리고 패키지를 설치한다.
pip install --no-cache-dir -r requirements.txt
이제 크롤링 python 샘플 코드를 아래와 같이 작성한다. 내용은 '네이버 뉴스검색'에서 키워드를 검색하고 그 결과를 출력하는 로직이다. 결과는 뉴스의 제목과 링크URL만 출력한다.
import requests
from bs4 import BeautifulSoup
keyword = '자전거' # 검색할 키워드
raw = requests.get('https://search.naver.com/search.naver?&where=news&query=' + keyword).text
html = BeautifulSoup(raw, 'html.parser')
articles = html.select('.list_news > li') # 뉴스 article select
for article in articles:
title = article.select_one('div.news_area > a').text # 제목
url = article.select_one('div.news_area > a')['href'] # 링크URL
print(title, url) # 출력아래는 네이버뉴스의 html 구조이다. <li>태그들로 각 기사들이 구분이 되어 있고, 개별 기사 내부의 <a>태그에서 제목과 링크URL을 가져온다.
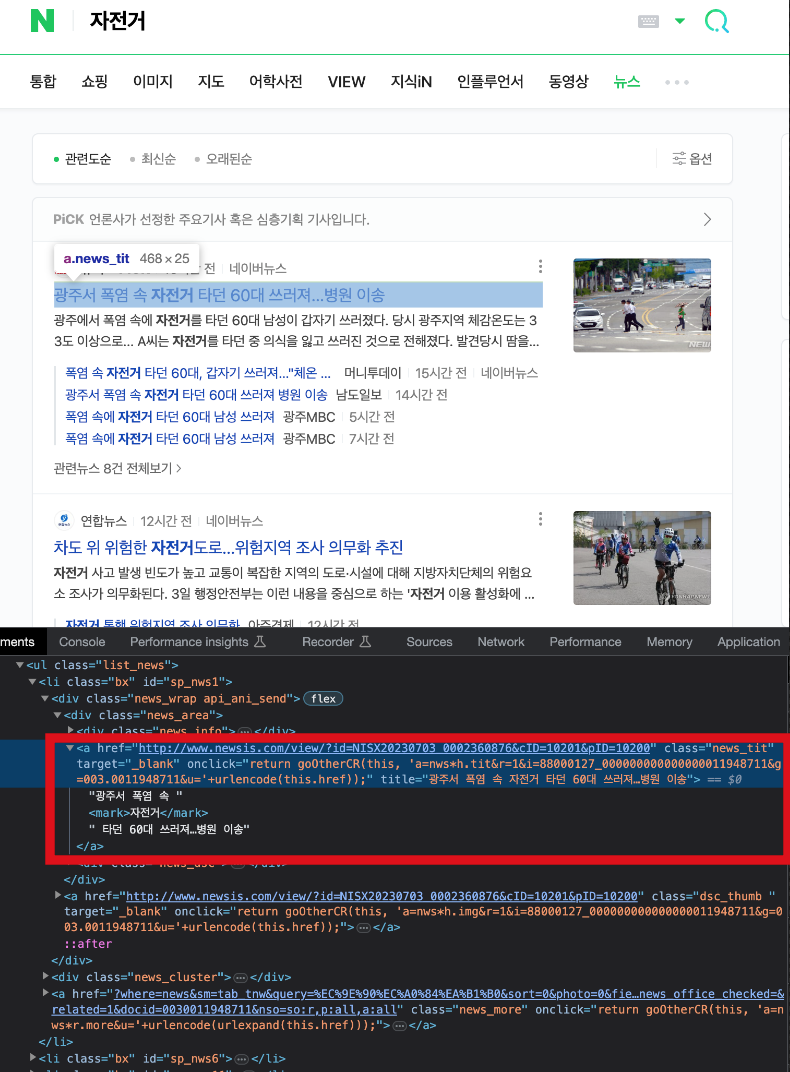
이제 실행만 하면 아래와 같이 결과가 나온다.
python crawling.py
반응형

댓글